Amazon EKS Core Services
Overview
This service contains Terraform and Helm code to deploy core administrative services, such as FluentD and the ALB Ingress Controller, onto Elastic Kubernetes Service(EKS).
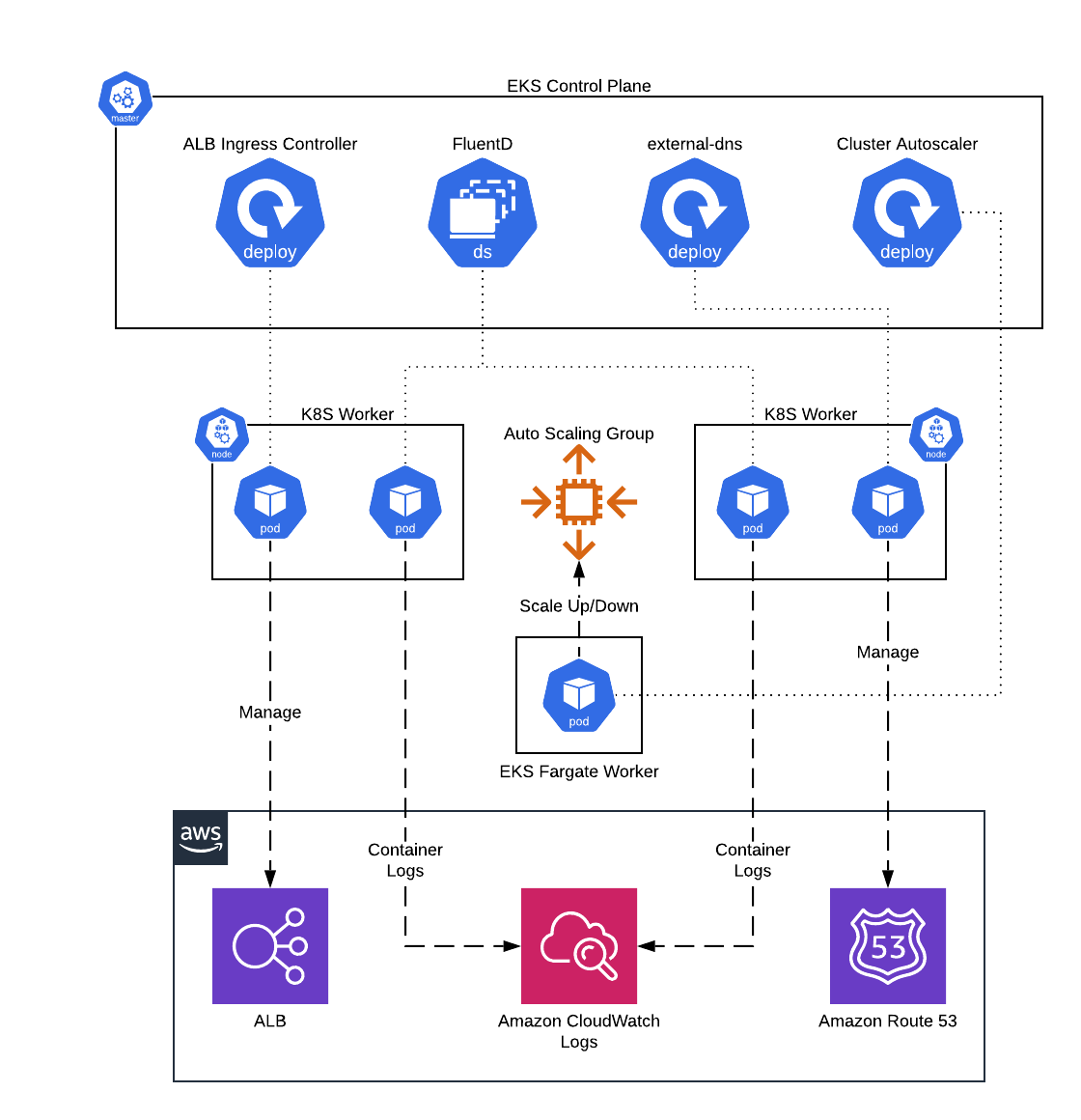 EKS Core Services architecture
EKS Core Services architecture
Features
- Deploy FluentD DaemonSet to ship container logs to CloudWatch Logs
- Deploy ALB Ingress Controller to configure ALBs from within Kubernetes
- Deploy external-dns to manage Route 53 DNS records from within Kubernetes
- Deploy Kubernetes cluster-autoscaler to configure auto scaling of ASGs based on Pod demand
- Deploy AWS CloudWatch Agent to configure container and node level metrics from worker nodes
Learn
note
This repo is a part of the Gruntwork Service Catalog, a collection of reusable, battle-tested, production ready infrastructure code. If you’ve never used the Service Catalog before, make sure to read How to use the Gruntwork Service Catalog!
Under the hood, this is all implemented using Terraform modules from the Gruntwork terraform-aws-eks repo. If you are a subscriber and don’t have access to this repo, email support@gruntwork.io.
Core concepts
For information on each of the core services deployed by this service, see the documentation in the terraform-aws-eks repo.
Repo organization
- modules: the main implementation code for this repo, broken down into multiple standalone, orthogonal submodules.
- examples: This folder contains working examples of how to use the submodules.
- test: Automated tests for the modules and examples.
Deploy
Non-production deployment (quick start for learning)
If you just want to try this repo out for experimenting and learning, check out the following resources:
- examples/for-learning-and-testing folder: The
examples/for-learning-and-testingfolder contains standalone sample code optimized for learning, experimenting, and testing (but not direct production usage).
Production deployment
If you want to deploy this repo in production, check out the following resources:
examples/for-production folder: The
examples/for-productionfolder contains sample code optimized for direct usage in production. This is code from the Gruntwork Reference Architecture, and it shows you how we build an end-to-end, integrated tech stack on top of the Gruntwork Service Catalog.How to deploy a production-grade Kubernetes cluster on AWS: A step-by-step guide for deploying a production-grade EKS cluster on AWS using the code in this repo.
Reference
- Inputs
- Outputs
Required
aws_regionstring(required)The AWS region in which all resources will be created
eks_cluster_namestring(required)The name of the EKS cluster where the core services will be deployed into.
eks_iam_role_for_service_accounts_configobject(required)Configuration for using the IAM role with Service Accounts feature to provide permissions to the applications. This expects a map with two properties: openid_connect_provider_arn and openid_connect_provider_url. The openid_connect_provider_arn is the ARN of the OpenID Connect Provider for EKS to retrieve IAM credentials, while openid_connect_provider_url is the URL. Set to null if you do not wish to use IAM role with Service Accounts.
object({
openid_connect_provider_arn = string
openid_connect_provider_url = string
})
pod_execution_iam_role_arnstring(required)ARN of IAM Role to use as the Pod execution role for Fargate. Required if any of the services are being scheduled on Fargate. Set to null if none of the Pods are being scheduled on Fargate.
vpc_idstring(required)The ID of the VPC where the EKS cluster is deployed.
worker_vpc_subnet_idslist(required)The subnet IDs to use for EKS worker nodes. Used when provisioning Pods on to Fargate. Required if any of the services are being scheduled on Fargate. Set to empty list if none of the Pods are being scheduled on Fargate.
list(string)
Optional
alb_ingress_controller_pod_node_affinitylist(optional)Configure affinity rules for the ALB Ingress Controller Pod to control which nodes to schedule on. Each item in the list should be a map with the keys key, values, and operator, corresponding to the 3 properties of matchExpressions. Note that all expressions must be satisfied to schedule on the node.
list(object({
key = string
values = list(string)
operator = string
}))
[]alb_ingress_controller_pod_tolerationslist(optional)Configure tolerations rules to allow the ALB Ingress Controller Pod to schedule on nodes that have been tainted. Each item in the list specifies a toleration rule.
list(map(any))
[]autoscaler_down_delay_after_addstring(optional)Minimum time to wait after a scale up event before any node is considered for scale down.
10mautoscaler_scale_down_unneeded_timestring(optional)Minimum time to wait since the node became unused before the node is considered for scale down by the autoscaler.
10mautoscaler_skip_nodes_with_local_storagebool(optional)If true cluster autoscaler will never delete nodes with pods with local storage, e.g. EmptyDir or HostPath
trueaws_cloudwatch_agent_image_repositorystring(optional)The Container repository to use for looking up the cloudwatch-agent Container image when deploying the pods. When null, uses the default repository set in the chart. Only applies to non-fargate workers.
nullaws_cloudwatch_agent_pod_node_affinitylist(optional)Configure affinity rules for the AWS CloudWatch Agent Pod to control which nodes to schedule on. Each item in the list should be a map with the keys key, values, and operator, corresponding to the 3 properties of matchExpressions. Note that all expressions must be satisfied to schedule on the node.
list(object({
key = string
values = list(string)
operator = string
}))
[]aws_cloudwatch_agent_pod_resourcesany(optional)Pod resource requests and limits to use. Refer to https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ for more information.
nullaws_cloudwatch_agent_pod_tolerationslist(optional)Configure tolerations rules to allow the AWS CloudWatch Agent Pods to schedule on nodes that have been tainted. Each item in the list specifies a toleration rule.
list(map(any))
[]aws_cloudwatch_agent_versionstring(optional)Which version of amazon/cloudwatch-agent to install. When null, uses the default version set in the chart. Only applies to non-fargate workers.
nullcluster_autoscaler_pod_annotationsmap(optional)Annotations to apply to the cluster autoscaler pod(s), as key value pairs.
map(string)
{}cluster_autoscaler_pod_labelsmap(optional)Labels to apply to the cluster autoscaler pod(s), as key value pairs.
map(string)
{}cluster_autoscaler_pod_node_affinitylist(optional)Configure affinity rules for the cluster-autoscaler Pod to control which nodes to schedule on. Each item in the list should be a map with the keys key, values, and operator, corresponding to the 3 properties of matchExpressions. Note that all expressions must be satisfied to schedule on the node.
list(object({
key = string
values = list(string)
operator = string
}))
[]cluster_autoscaler_pod_resourcesany(optional)Pod resource requests and limits to use. Refer to https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/ for more information. This is most useful for configuring CPU+Memory availability for Fargate, which defaults to 0.25 vCPU and 256MB RAM.
{
limits = {
cpu = "250m",
memory = "1024Mi"
},
requests = {
cpu = "250m",
memory = "1024Mi"
}
}
cluster_autoscaler_pod_tolerationslist(optional)Configure tolerations rules to allow the cluster-autoscaler Pod to schedule on nodes that have been tainted. Each item in the list specifies a toleration rule.
list(map(any))
[]cluster_autoscaler_release_namestring(optional)The name to use for the helm release for cluster-autoscaler. This is useful to force a redeployment of the cluster-autoscaler component.
cluster-autoscalercluster_autoscaler_repositorystring(optional)Which docker repository to use to install the cluster autoscaler. Check the following link for valid repositories to use https://github.com/kubernetes/autoscaler/releases
us.gcr.io/k8s-artifacts-prod/autoscaling/cluster-autoscalercluster_autoscaler_scaling_strategystring(optional)Specifies an 'expander' for the cluster autoscaler. This helps determine which ASG to scale when additional resource capacity is needed.
least-wastecluster_autoscaler_versionstring(optional)Which version of the cluster autoscaler to install. This should match the major/minor version (e.g., v1.20) of your Kubernetes Installation. See https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler#releases for a list of versions.
v1.21.0enable_alb_ingress_controllerbool(optional)Whether or not to enable the AWS LB Ingress controller.
trueenable_aws_cloudwatch_agentbool(optional)Whether to enable the AWS CloudWatch Agent DaemonSet for collecting container and node metrics from worker nodes (self-managed ASG or managed node groups).
trueenable_cluster_autoscalerbool(optional)Whether or not to enable cluster-autoscaler for Autoscaling EKS worker nodes.
trueenable_external_dnsbool(optional)Whether or not to enable external-dns for DNS entry syncing with Route 53 for Services and Ingresses.
trueenable_fargate_fluent_bitbool(optional)Whether or not to enable fluent-bit on EKS Fargate workers for log aggregation.
trueenable_fluent_bitbool(optional)Whether or not to enable fluent-bit for log aggregation.
trueexternal_dns_pod_node_affinitylist(optional)Configure affinity rules for the external-dns Pod to control which nodes to schedule on. Each item in the list should be a map with the keys key, values, and operator, corresponding to the 3 properties of matchExpressions. Note that all expressions must be satisfied to schedule on the node.
list(object({
key = string
values = list(string)
operator = string
}))
[]external_dns_pod_tolerationslist(optional)Configure tolerations rules to allow the external-dns Pod to schedule on nodes that have been tainted. Each item in the list specifies a toleration rule.
list(map(any))
[]external_dns_route53_hosted_zone_domain_filterslist(optional)Only create records in hosted zones that match the provided domain names. Empty list (default) means match all zones. Zones must satisfy all three constraints (external_dns_route53_hosted_zone_tag_filters, external_dns_route53_hosted_zone_id_filters, and external_dns_route53_hosted_zone_domain_filters).
list(string)
[]external_dns_route53_hosted_zone_id_filterslist(optional)Only create records in hosted zones that match the provided IDs. Empty list (default) means match all zones. Zones must satisfy all three constraints (external_dns_route53_hosted_zone_tag_filters, external_dns_route53_hosted_zone_id_filters, and external_dns_route53_hosted_zone_domain_filters).
list(string)
[]external_dns_route53_hosted_zone_tag_filterslist(optional)Only create records in hosted zones that match the provided tags. Each item in the list should specify tag key and tag value as a map. Empty list (default) means match all zones. Zones must satisfy all three constraints (external_dns_route53_hosted_zone_tag_filters, external_dns_route53_hosted_zone_id_filters, and external_dns_route53_hosted_zone_domain_filters).
list(object({
key = string
value = string
}))
[]external_dns_sourceslist(optional)K8s resources type to be observed for new DNS entries by ExternalDNS.
list(string)
[
"ingress",
"service"
]
fargate_fluent_bit_execution_iam_role_arnslist(optional)List of ARNs of Fargate execution IAM Roles that should get permissions to ship logs using fluent-bit. This must be provided if enable_fargate_fluent_bit is true.
list(string)
[]fargate_fluent_bit_extra_filtersstring(optional)Additional filters that fluent-bit should apply to log output. This string should be formatted according to the Fluent-bit docs (https://docs.fluentbit.io/manual/administration/configuring-fluent-bit/configuration-file#config_filter).
""fargate_fluent_bit_extra_parsersstring(optional)Additional parsers that fluent-bit should export logs to. This string should be formatted according to the Fluent-bit docs (https://docs.fluentbit.io/manual/administration/configuring-fluent-bit/configuration-file#config_output).
""fargate_fluent_bit_log_stream_prefixstring(optional)Prefix string to use for the CloudWatch Log Stream that gets created for each Fargate pod.
fargatefargate_worker_disallowed_availability_zoneslist(optional)A list of availability zones in the region that we CANNOT use to deploy the EKS Fargate workers. You can use this to avoid availability zones that may not be able to provision the resources (e.g ran out of capacity). If empty, will allow all availability zones.
list(string)
[
"us-east-1d",
"us-east-1e",
"ca-central-1d"
]
fluent_bit_extra_filtersstring(optional)Additional filters that fluent-bit should apply to log output. This string should be formatted according to the Fluent-bit docs (https://docs.fluentbit.io/manual/administration/configuring-fluent-bit/configuration-file#config_filter).
""fluent_bit_extra_outputsstring(optional)Additional output streams that fluent-bit should export logs to. This string should be formatted according to the Fluent-bit docs (https://docs.fluentbit.io/manual/administration/configuring-fluent-bit/configuration-file#config_output).
""fluent_bit_image_repositorystring(optional)The Container repository to use for looking up the aws-for-fluent-bit Container image when deploying the pods. When null, uses the default repository set in the chart. Only applies to non-fargate workers.
nullfluent_bit_log_group_already_existsbool(optional)If set to true, that means that the CloudWatch Log Group fluent-bit should use for streaming logs already exists and does not need to be created.
falsefluent_bit_log_group_kms_key_idstring(optional)The ARN of the KMS key to use to encrypt the logs in the CloudWatch Log Group used for storing container logs streamed with FluentBit. Set to null to disable encryption.
nullfluent_bit_log_group_namestring(optional)Name of the CloudWatch Log Group fluent-bit should use to stream logs to. When null (default), uses the eks_cluster_name as the Log Group name.
nullfluent_bit_log_group_retentionnumber(optional)number of days to retain log events. Possible values are: 1, 3, 5, 7, 14, 30, 60, 90, 120, 150, 180, 365, 400, 545, 731, 1827, 3653, and 0. Select 0 to never expire.
0fluent_bit_log_group_subscription_arnstring(optional)ARN of the lambda function to trigger when events arrive at the fluent bit log group.
nullfluent_bit_log_group_subscription_filterstring(optional)Filter pattern for the CloudWatch subscription. Only used if fluent_bit_log_group_subscription_arn is set.
""fluent_bit_log_stream_prefixstring(optional)Prefix string to use for the CloudWatch Log Stream that gets created for each pod. When null (default), the prefix is set to 'fluentbit'.
nullfluent_bit_pod_node_affinitylist(optional)Configure affinity rules for the fluent-bit Pods to control which nodes to schedule on. Each item in the list should be a map with the keys key, values, and operator, corresponding to the 3 properties of matchExpressions. Note that all expressions must be satisfied to schedule on the node.
list(object({
key = string
values = list(string)
operator = string
}))
[]fluent_bit_pod_tolerationslist(optional)Configure tolerations rules to allow the fluent-bit Pods to schedule on nodes that have been tainted. Each item in the list specifies a toleration rule.
list(map(any))
[]fluent_bit_versionstring(optional)Which version of aws-for-fluent-bit to install. When null, uses the default version set in the chart. Only applies to non-fargate workers.
nullroute53_record_update_policystring(optional)Policy for how DNS records are sychronized between sources and providers (options: sync, upsert-only).
syncschedule_alb_ingress_controller_on_fargatebool(optional)When true, the ALB ingress controller pods will be scheduled on Fargate.
falseschedule_cluster_autoscaler_on_fargatebool(optional)When true, the cluster autoscaler pods will be scheduled on Fargate. It is recommended to run the cluster autoscaler on Fargate to avoid the autoscaler scaling down a node where it is running (and thus shutting itself down during a scale down event). However, since Fargate is only supported on a handful of regions, we don't default to true here.
falseschedule_external_dns_on_fargatebool(optional)When true, the external-dns pods will be scheduled on Fargate.
falseservice_dns_mappingsmap(optional)Configure Kubernetes Services to lookup external DNS records. This can be useful to bind friendly internal service names to domains (e.g. the RDS database endpoint).
map(object({
# DNS record to route requests to the Kubernetes Service to.
target_dns = string
# Port to route requests
target_port = number
# Namespace to create the underlying Kubernetes Service in.
namespace = string
}))
{}use_exec_plugin_for_authbool(optional)If this variable is set to true, then use an exec-based plugin to authenticate and fetch tokens for EKS. This is useful because EKS clusters use short-lived authentication tokens that can expire in the middle of an 'apply' or 'destroy', and since the native Kubernetes provider in Terraform doesn't have a way to fetch up-to-date tokens, we recommend using an exec-based provider as a workaround. Use the use_kubergrunt_to_fetch_token input variable to control whether kubergrunt or aws is used to fetch tokens.
trueuse_kubergrunt_to_fetch_tokenbool(optional)EKS clusters use short-lived authentication tokens that can expire in the middle of an 'apply' or 'destroy'. To avoid this issue, we use an exec-based plugin to fetch an up-to-date token. If this variable is set to true, we'll use kubergrunt to fetch the token (in which case, kubergrunt must be installed and on PATH); if this variable is set to false, we'll use the aws CLI to fetch the token (in which case, aws must be installed and on PATH). Note this functionality is only enabled if use_exec_plugin_for_auth is set to true.
trueuse_managed_iam_policiesbool(optional)When true, all IAM policies will be managed as dedicated policies rather than inline policies attached to the IAM roles. Dedicated managed policies are friendlier to automated policy checkers, which may scan a single resource for findings. As such, it is important to avoid inline policies when targeting compliance with various security standards.
trueName of the CloudWatch Log Group used to store the container logs.